El Estudiante químico de la Guinness, propulsor del I+D- Capital Cities - Safe and sound
La Ciencia, esa desconocida.
I could lift you up
I could show you what you want to see
And take you where you want to be
You could be my luck
Even if the sky is falling down
I know that we'll be safe and sound
We're safe and sound
I could fill your cup
You know my river won't evaporate
This world we still appreciate
You could be my luck
Even in a hurricane of frowns
I know that we'll be safe and sound -safe and sound-
We're safe and sound -safe and sound-
We're safe and sound -on your ground-
We're safe and sound -safe and sound-
I could show you love
In a tidal-wave of mystery
You'll still be standing next to me
You could be my luck
Even if we're six feet under ground
I know that we'll be safe and sound
We're safe and sound
-Safe and sound, safe and sound-
-On your ground, safe and sound-
I could lift you up
I could show you what you want to see
And take you where you want to be
You could be my luck
Even if the sky is falling down
I know that we'll be safe and sound
I could lift you up
I could show you what you want to see
And take you where you want to be
You could be my luck
Even if the sky is falling down
I know that we'll be safe and sound
We're safe and sound
We're safe and sound
We're safe and sound
We're safe and sound -safe and sound-
We're safe and sound -safe and sound-
We're safe and sound -on your ground-
We're safe and sound -safe and sound-
We're safe and sound
Capital Cities - Safe and sound
THE PROBABLE ERROR OF A MEAN By STUDENT
http://www.york.ac.uk/depts/maths/histstat/student.pdf
 |
| W. Gosset, químico que trabajó para la Guinnes, nos ha dejado un instrumento estadístico de contraste firmado como "t de Student". Es mi pequeño homenaje a un gran hombre que nunca dejó de estudiar. |
Son algunas tareas a las que nos enfrentamos cuando intentamos medir y cuantificar una variable objeto de estudio expresada la problemática mediante una hipótesis.
- Identificar, describir, caracterizar, establecer los antecedentes, establecer relaciones, explicar las causas, establecer factores, explicar los efectos.
Una variable puede ser:
Los niveles de investigación pueden ser:
- una característica, una propiedad objeto de estudio, un fenómeno, un individuo, un sustantivo, un hecho social, un aspecto o dimensión del fenómeno, una manifestación de la realidad.
- exploratorio, descriptivo, correlacional, explicativo.
Las escalas de medida:
Tipos de variables:
- Nominal, ordinal, intervalo y de razón.
- Cualitativa (nominal) dicotómica o politónica
- Cuasicuantitativa (ordinal) discreta o continua
- Independiente, la causa
- Dependiente, efecto
- Extraña, influye en la dependiente pero no interesa en el estudio
En la Babel Científica Mundial, necesitamos expresar nuestras hipótesis y teorías, siendo conscientes de que en la otra parte del planeta pueden estar interesados en leer nuestro artículo. Como norma los artículos se expresan en ingles, idioma que después de la segunda guerra mundial se erigió como el idioma de la ciencia. En esos informes quedan plasmadas observaciones que se han realizado en un laboratorio o en la propia realidad de una comunidad, que puede ser tan amplia como un continente o tan pequeña como un aula o un tubo de ensayo. Se pueden haber utilizado el método experimental o el método cuasiexperimental. Se ha realizado un modelo que representa lo que se desea describir, explicar y predecir. Y el trabajo del investigador es realizar:
Con ello estamos siguiendo los pasos del Método Científico para hacer Ciencia, que hoy por hoy, y a mi entender, es lo más cercano a la "objetividad" que se puede dar.
- Una abstracción y representación simbólica que permite con diagramas, números, palabras y otros signos a los cuales se les ha asignado un significado, describir características de los sucesos que estamos observando, estableciendo patrones.
- Una vez establecidos los patrones hay que representar la investigación de forma ordenada para poder transmitir al resto de la comunidad científica nuestros resultados, y para ello se usa el lenguaje matemático. el objeto de investigación debe ser público para que otros investigadores puedan realizar los pasos para llegar a la conclusión inicial, si no se llega a esa conclusión se refuta la conclusión aportando la evidencia en contra.
Estimación de parámetros y constaste de hipótesis
Un estimador
es un estadístico (muestral) que se utiliza para estimar un parámetro (población).
- Los estadísticos son estimadores de las muestras y se representan con letras latina
- Los parámetros son estimadores poblacionales y se representan con letras griegas
Distribuciones muestrales
La inferencia estadística:
Para cada
característica evaluada se obtiene uno, o más, valores numéricos que se conocen como estadísticos:
Y es a
partir de los diversos estadísticos
obtenidos en la muestra (lo concreto) que tiene que realizar afirmaciones
sobre los valores de los parámetros de la población (lo general).
Distribución muestral
Hay que situarse en un plano hipotético en el que pudiéramos trabajar
con todas las posibles muestras del
mismo tamaño, n, que se pueden extraer de una población de tamaño N (siendo N > n).
El estadístico obtenido en cada una de las
distintas muestras se comporta como una variable
aleatoria
Como en
toda distribución de probabilidad, también de la distribución muestral de uno
de estos estadísticos obtenido para todas las muestras posibles, podemos
obtener su media y su desviación típica.
De modo
que el concepto de distribución muestral hay que distinguirlo de otros tipos de
distribuciones, como son:
La forma que adopta la distribución muestral depende, entre otras cosas, de la forma que adopte la distribución poblacional. 
Distribución muestral de la media
La media muestral es una variable aleatoria que toma un valor
según la muestra concreta que se obtenga.
La media como estimador
El error típico de la media es un indicador de la precisión de la
estimación de la media; cuanto menor es el error típico, mayor es la precisión.
Depende de
la desviación típica de la población y del tamaño de la muestra.
Un
estimador es un estadístico que se utiliza para estimar (evaluar) un parámetro.
El error típico de la
media es un indicador de la precisión de la estimación de la media; cuanto menor es el
error típico, mayor es la precisión.
La distribución
muestral de un estadístico es un concepto central, tanto de la estimación como del contraste de hipótesis.
Consideremos
una población formada por todos los estudiantes universitarios de
una determinada comunidad de los que podemos conocer, a partir de sus datos de
la matrícula, su edad.
A partir
de estos datos (de la población de estudiantes universitarios de una
comunidad) podemos calcular su edad
media y la varianza de esta misma variable (edad), valores que representamos
por:

Si dispusiéramos de más
de una variable, sería recomendable indicar, mediante subíndices, a qué
variable se corresponde cada media y varianza, de tal forma que en este caso
podríamos indicarlo como:

De esta
población podemos extraer una muestra
de, por ejemplo, 100 estudiantes y
calcular su media y desviación típica que representamos por:

Pero esta
muestra no es la única posible. Se
pueden extraer muchas otras muestras diferentes, todas ellas del mismo tamaño (n=100) en
cada una de ellas calcular su media y desviación típica que pueden variar de
una muestra a otra, de tal manera que con las puntuaciones de todas las medias
obtenidas en estas distintas muestras se origina otra
distribución que se llama distribución muestral de la media.

Con el
mismo procedimiento se obtendría la distribución muestral de la desviación
típica o de cualquier otro estadístico, como la proporción, la correlación de
Pearson, etc. y corresponde a la distribución de probabilidad de un estadístico
que se obtiene al calcularlo en todas las posibles muestras del mismo tipo y tamaño, n, extraídas de una
población de tamaño N.
La
distribución muestral de la media es normal, o se aproxima suficientemente a la
normalidad, cuando se cumple al menos una de las siguientes condiciones:
Recordamos:
Media, varianza y desviación típica de la variable cuantitativa X en la
población, en la muestra y la distribución muestral de la media.

Cuando
realizamos inferencia estadística sobre la media aritmética, siempre ha de
cumplirse al menos una de las dos condiciones descritas, pero procederemos
de forma diferente en función de si la varianza poblacional es conocida o
desconocida.
Si conocemos
la desviación típica poblacional σ
Podemos asumir que la variable en
la población se distribuye normalmente, o bien n es mayor que 30, entonces consideramos que la distribución
muestral del estadístico media es también normal, cuya media y desviación típica
(o error típico de la media) son, respectivamente:

Si
tipificamos el valor del estadístico media que se
distribuye normalmente, obtenemos la variable Z:

Cuya distribución
será normal, N (0, 1), lo cual permite conocer mediante las tablas de la
curva normal la probabilidad asociada a cada valor del estadístico de la media en
la distribución muestral, o la distancia, desde la media de una muestra concreta, a la media de la población (que coincide con la media de la distribución muestral).
  
Propiedades básicas de la distribución normal (campana de Gauss)

Áreas y proporciones bajo la curva
normal:
Columna (Z):
 
No conocemos la varianza de la variable en la población
Pero podemos asumir que la
distribución poblacional es normal o bien n es mayor o igual que 30, los estudios realizados por W. S. Gosset al
final del siglo XIX demostró que en estas circunstancias la distribución
muestral de la media es una distribución diferente de la normal, que se conoce
con el nombre de distribución t de Student.

Sigue
el modelo t de Student con n-1 grados de libertad, donde Sn-1 y
Sn son, respectivamente, la cuasidesviación típica y la desviación
típica de la muestra.
Propiedades de la distribución t de Student:

Partimos de una
distribución poblacional normalmente distribuida con media 50 y desviación
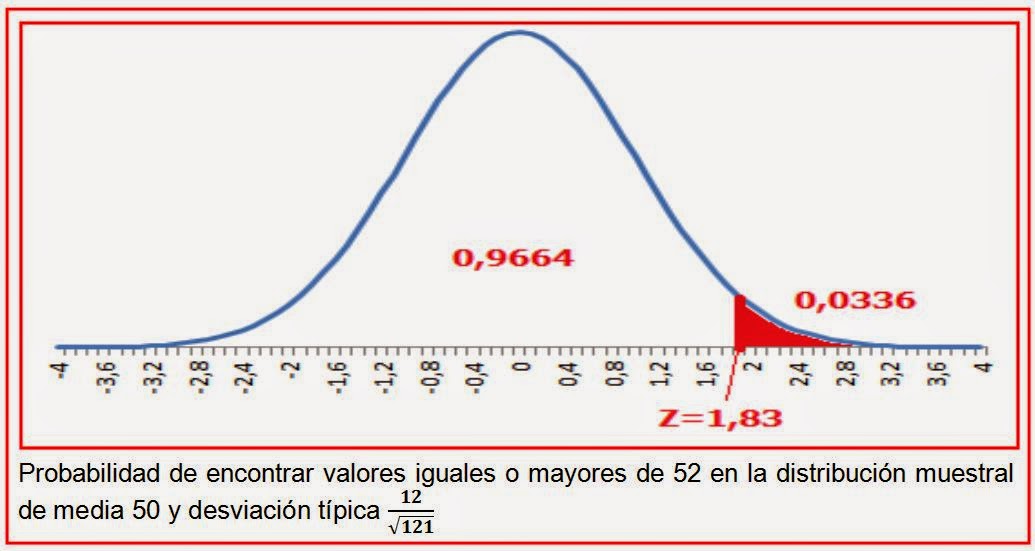
típica 12 por lo que la distribución muestral de la media es también normal.

¿Cuál es la probabilidad de
obtener una media de 52 puntos o superior?
Calculamos
la puntuación típica correspondiente al valor 52, en la distribución muestral
de medias:
 
De
acuerdo a la distribución normal tipificada:
Realizamos la siguiente resta 1-0,9664=0,0336, es decir, restamos a la unidad, que es el valor total del interior de la curva, el valor que hemos sacado en el estadístico de contraste tipificado, mirando en el interior de la tabla Z.

Es poco probable
encontrar en esa población una muestra de 121 elementos y que tenga 52 puntos
de media o superior. Se
representa el área correspondiente a esta probabilidad.
¿Cuál es la probabilidad de
obtener una media que esté comprendida entre 48 y 51 puntos?
Calculamos la puntuación típica correspondiente al valor 48 y 51, en la distribución muestral de medias:

Realizamos
los mismos pasos anteriores en la tabla Z con los resultados obtenidos:
Resultado realizando la siguiente resta:

De
acuerdo a la distribución normal tipificada la probabilidad, comprendida entre
estas dos puntuaciones que se representa a continuación.
  
Distribución muestral
de la proporción
Sea X una variable que sólo toma valores 0 y 1, variable dicotómica, la
proporción de la muestra P se define como:
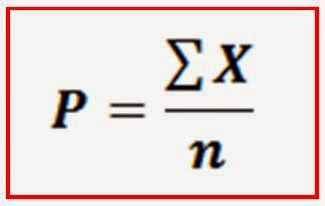
Dado el muestreo aleatorio simple, el estadístico
proporción (P) se distribuye según una binomial:
 
Como P es la media de los valores de X en la
muestra, según el Teorema Central del Límite, a medida que el tamaño crece, la
distribución muestral de la proporción tiende a la normal con:

Cuanto más alejado esté de 0,5, más elementos debe tener la muestra para realizar la aproximación a la normal.
En
estas situaciones tenemos que apoyarnos en la distribución muestral de la proporción,
la cual se genera con la misma lógica que la distribución muestral de la media,
con la única diferencia de que al extraer todas las posibles muestras de tamaño
n de la población, el estadístico que se calcula en cada una de ellas es la
proporción donde:
Si llamamos pi a la
proporción de casos que cumplen una determinada condición en una población de
tamaño N y extraemos todas las posibles muestras aleatorias de tamaño n,
en la que definimos la variable p = “Proporción de aciertos”, la
distribución muestral de la proporción es la distribución de probabilidad del
conjunto de todas las proporciones, p, obtenidas en todas las muestras posibles
de tamaño n, extraídas de una población de tamaño N. La variable aleatoria p,
sigue el modelo de probabilidad binomial, cuya media y desviación típica
son, respectivamente:
  
Media, varianza y desviación típica de la
variable dicotómica o dicotomizada (X) en la población, en la muestra y la
distribución muestral de la proporción (P):

Las probabilidades
asociadas a cada valor de p se pueden buscar en las tablas de
distribución binomial con parámetros n y pi.

Ejemplo
1.2: Una escuela de educación primaria está compuesta por un 40% de
niños y un 60% de niñas. Si se elige una muestra aleatoria de 20 alumnos, ¿cuál
será la probabilidad de que haya más de 9 niños?
La
probabilidad de que en una muestra de 20 alumnos haya más de 9 niños, siendo la
proporción de éstos en la población:

En
Ciencias Sociales y de la Salud se trabajan con variables que toman solo dos
valores (dicotómicas 1 – 0). En este caso se utiliza la distribución
binomial.
Una
variable aleatoria X sigue una distribución binomial (con parámetros n y p) si
expresa el numero de realizaciones independientes “n”
con la probabilidad “p” y por tanto (1 –
p) de obtener fracaso.

Se
obtiene recurriendo a la distribución
binomial con parámetros:
 La probabilidad pedida es, utilizando la expresión de su función de distribución, la siguiente:  
Y
utilizando la distribución normal,
tipificamos la proporción de niños obtenida en la muestra:
 
Los
resultados obtenidos por los dos procedimientos no coinciden pero la diferencia
encontrada va desapareciendo a medida que aumenta el tamaño de la muestra, ya
que el ajuste de la distribución binomial a la normal con este incremento de n
es más preciso.

Esta
diferencia entre la probabilidad calculada mediante la distribución discreta
binomial y la calculada
mediante la curva normal se debe a que la
curva normal es continua.
Repetimos
los pasos anteriores obtendríamos un valor de 0,2483, bastante cercano al
inicial (0,2447).

Efecto
de utilizar y = 9 ó y = 9,5 sobre las probabilidades para calcular la
aproximación de la normal a la binomial.
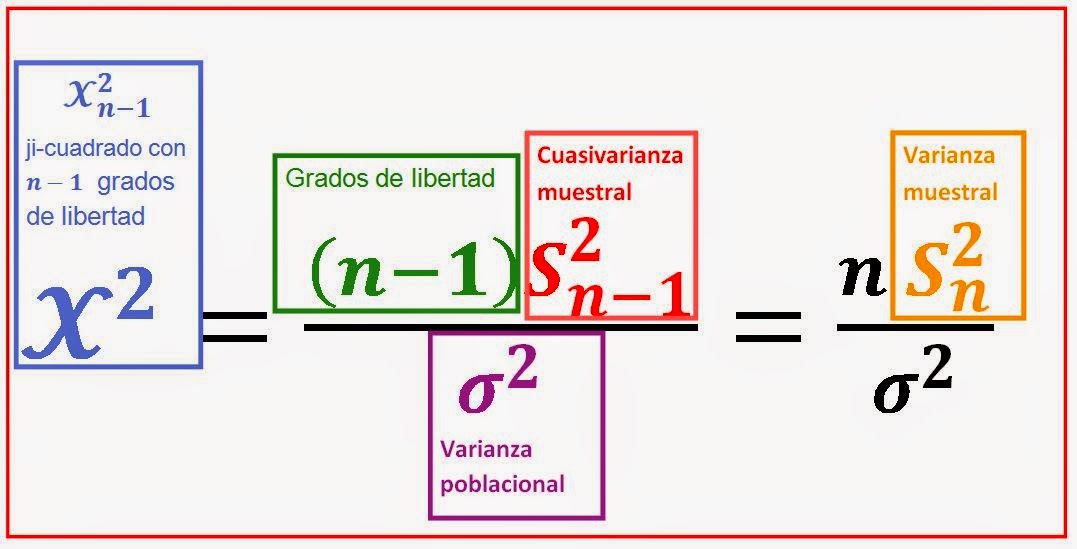
Distribución muestral de la varianza
La
varianza es una medida de dispersión que permite determinar la variabilidad que
presentan los datos para la variable objeto de estudio.

La
variable aleatoria que permite realizar afirmaciones sobre la varianza
poblacional se puede generar a partir de la cuasivarianza o la varianza de la
muestra:
En
este caso para cada muestra calculamos el valor de ji-cuadrado, para el cual necesitamos calcular la
varianza (o cuasi-varianza) muestral, así como conocer el valor de la varianza en la población.
Teniendo
en cuenta este modelo de probabilidad de la variable aleatoria así definida, su
media y desviación típica son, respectivamente:

Ejemplo 1.3: Supongamos que la altura (en centímetros)
de los recién nacidos en Méjico se distribuye normalmente con media 48 cm y
desviación típica 6 cm, es decir, N (48; 6). Si se selecciona una muestra de 25
recién nacidos, ¿cuál es la probabilidad de que la desviación típica de la
muestra tome un valor inferior a 4,75 centímetros?
Utilizando
la desviación típica de la muestra, el valor de la variable aleatoria es:
 
Por
tanto, la probabilidad de que una muestra de 25 recién nacidos tenga una desviación típica inferior a 4,75 centímetros (o una varianza
inferior a 4,752) es aproximadamente de 0,10.
La inferencia o generalización de lo particular a lo general, se realiza mediante dos procedimientos íntimamente relacionados:
El muestreo aleatorio tiene que cumplir dos condiciones:
De
esta forma, una muestra representativa es una reproducción, a escala, de la
población a la que pertenece respecto a la o las variables que tratamos de estudiar.
Estimación de parámetros. Propiedades de los estimadores.
Un
estimador es un estadístico calculado en una muestra que se utiliza para estimar un parámetro poblacional.
Para
que un estimador realice buenas estimaciones
del parámetro poblacional es preciso que tenga las cuatro propiedades que de forma muy resumida expondremos en las
siguientes líneas.
Para
desvincular las propiedades de los estimadores de un parámetro concreto,
designaremos de forma genérica con:

Esto
dependerá de la bondad de los mismos. Por lo tanto, es preciso saber qué hace
que un estadístico, u, sea un buen estimador del parámetro U. Obsérvese que para
denotar que un estadístico concreto es estimador de un parámetro, lo denotamos
poniendo el acento circunflejo sobre el parámetro a estimar.
¿Cuál de los posibles estimadores
deberíamos utilizar?
Esto
dependerá de la bondad de los mismos. Por lo tanto, es preciso saber qué hace
que un estadístico, u, sea un buen estimador del parámetro U. Obsérvese que para
denotar que un estadístico concreto es estimador de un parámetro, lo denotamos
poniendo el acento circunflejo sobre el parámetro a estimar.
De
esta forma, conceptualmente no es lo mismo:

Propiedades de los estimadores:

Los estadísticos cuando se aplican a los valores de las muestras que
extraemos de la población -y que habitualmente se representan con letras del
alfabeto latino son los estimadores que podemos utilizar para estimar los
parámetros poblacionales representados con letras del alfabeto griego.

La estimación de parámetros se realiza
siguiendo dos procedimientos:
Para
el cálculo del intervalo de confianza de la media hay que considerar las
circunstancias bajo las cuales la distribución muestral de la media es una
distribución normal o una distribución t de Student con n-1 grados de libertad.
El
cálculo del intervalo de confianza de la media aritmética se realiza:
En estas
circunstancias sabemos que la distribución muestral de la media es normal con
media, y desviación típica (o error típico de la
media) igual a la desviación típica poblacional dividida por la raíz cuadrada
de n:

Se trata, por tanto, de determinar dos
valores que definen un intervalo dentro del cual estimamos que se encontrará la
media poblacional, con una determinada probabilidad, que se denomina nivel de confianza.

Continuará.......
Páginas on line dedicadas a la protección de menores y ayudas clínicas Adicción a las nuevas tecnologías | ||
|---|---|---|
| Pantallas amigas | ||
| Protégeles | ||
| Menores en la red | ||
| Protege a tus hijos | ||
| Adicciones |



| Guía clínica del tratamiento de las adicciones |
| Tabaquismo |
| Instituto para el estudio de las adicciones |
| Drogas y cerebro |
| Agresiones sexuales |
| Guía de autoayuda |
| Centro de Asistencia a Víctimas de Agresiones Sexuales |
| Fundación Vicki Bernadet |
| Alcoholismo |
| Fundación de investigaciones sociales A.C |
| Instituto sevillano de adicciones |
| Anorexia y bulimia |


Comentarios
Publicar un comentario